Table of Contents
— layout: post title: "Notes — Tools of Data Visualization" permalink: :title category: Data Visualization tags: [Numpy, Pandas, Python, Data Visualization, Data Analysis] — <head> <meta http-equiv="Content-Type" content="text/html;charset=utf-8"> </head>
1 前言
本文属于整理的笔记,内容包含学习笔记,个人总结心得等等,保持持续更新,希望自己能坚持学习。 参考链接:
2 Anaconda
Anaconda以及Jupyter Notebook是数据分析的标准环境。Anaconda可以管理多个python版本环境:
- 管理包
- 管理环境
2.1 管理包
- 安装包 conda install package-name , e.g.:
- conda insatll pandas numpy (一次多个安装包)
- conda install numpy=1.10 (指定version)
- 卸载包 conda remove package-name
- 更新包 conda update package-name
- 列出已经安装的包 conda list
- 搜索名字不确定的包 conda search search-term, e.g. 如果不知道numpy怎么拼写的,则输入 conda search num
2.2 管理环境
conda为不同项目简历不同的运行环境
2.2.1 0. 安装nb-conda用于notebook自动关联nb-conda环境
conda install nb-conda
2.2.2 1. 创建环境
conda create -n env-name package-name
- env-name环境名称 package-name安装在环境中的包
- -n表示环境的名称name是env-name
e.g.在名为py3的环境中加入numpy: conda create -n py3 numpy
!!!创建环境时可以指定安装在环境中的python版本, 对于同时使用python2.x和python3.x时很有用。E.g.:
- 名为py3的环境中创建python3: conda create -n py3 python=3
- 名为py2的环境中创建python2: conda create -n py2 python=2
- 具体特定版本如python3.6: conda create -n py3 python=3.6
2.2.3 2. 进入环境
Linux下: source activate my-env 在环境中对包的管理如1.中所述,不过此时安装的包只在环境中使用
2.2.4 3. 离开环境
Linux下: source deactivate
2.2.5 4. 共享环境
让别人安装你的代码中使用的所有包以及正确的版本。 在当前环境中: conda env export > environment.yaml, 将当前环境保存.yaml文件(包含python版本和包名称),就可在刚刚的路径中看到此文件,其他电脑中就可以使用之前导出的环境。 举个例子,进入自己的环境py3, conda activate py3 更新环境 conda env update -f=/path/environment.yaml, 其中,-f表示要导出的文件在本地的路径。 如果别人不用conda,则 pip freeze > environment.txt,别人的电脑就可以使用 pip install -r /path/environment.txt
2.2.6 5.列出环境
conda env list
2.2.7 6. 删除环境
- conda remove –name py2 –all
- 或者 conda env remove -n env-name
2.3 例子
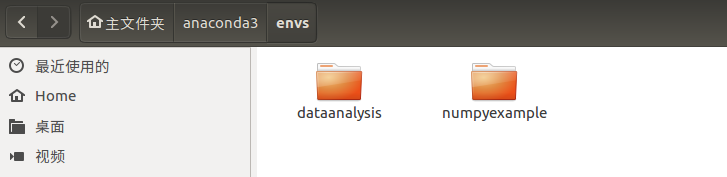
(以下例子为Ubuntu环境下)创建一个名为numpyexample的新环境:

中途会询问你是否在这个环境中下载某些包,最后心得环境建成后,得到以下提示告知你如何进入和退出一个环境:
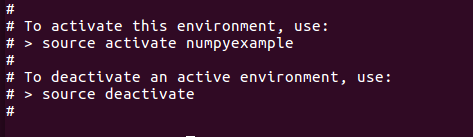
为了在jupyter notebook中打开conda环境并创建相应的kernel,还需要下载
$ conda install nb_conda ipykernel
输入source activate numpyexample即可进入到该环境。更改工作空间,输入jupyter notebook即可在notebook中打开一个项目。
2.4 Some tips about jupyter notebook
在使用jupyter notebook时可能会用到目录,方便查看,see more about conda-forge, [[https://zhuanlan.zhihu.com/p/24029578][添加目录到notebook].
conda config –append channels conda-forge conda install -c conda-forge jupyter_contrib_nbextensions
3 Numpy
Numpy有着较强的数字计算能力(基于numpy的开源python库Pandas以后再记录),是科学计算的开源python扩充库,是其他数据分析包的基础包,很多的包都是基于Numpy的,比如Pandas,NumPy为python提供了高性能的数组与矩阵运算能力。
3.1 Ndarray多维数组
| 函数 | 使用说明 |
|---|---|
| arrange(n) | 类似于内置的range函数,创建数组0~n-1 |
| ones((m,n)) | 创建指定形状的全1数组或矩阵mxn |
| ones\_like(arr1) | 根据矩阵arr1和它的dtype创建一个全1矩阵 |
| zeros,zeros_like | 同上,全0 |
| empty,empty_like | 同上,空 |
| eye(n,dtype='int32'),identity | 单位方阵 nxn |
3.1.1 创建多维数组
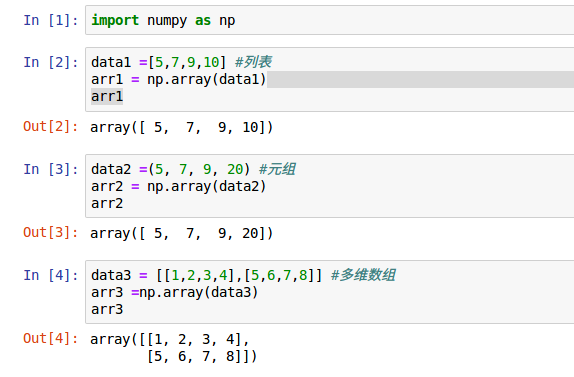
多维数组的创建可以从列表,元祖,多维数组,上述BIF等方式创立
| 列表 | [1,2,3,4] |
| 元祖 | (1,2,3,4) |
| 多维数组 | [[1,2,3,4],[1,2,3,4]] |
| 属性 | 解释 |
| shape (array.shape) | 形状,各个数组在数据轴上元素的个数 |
| dtype | 类型 |
| ndim | 数组轴的个数 |
| itemsize | 元素字节大小 |
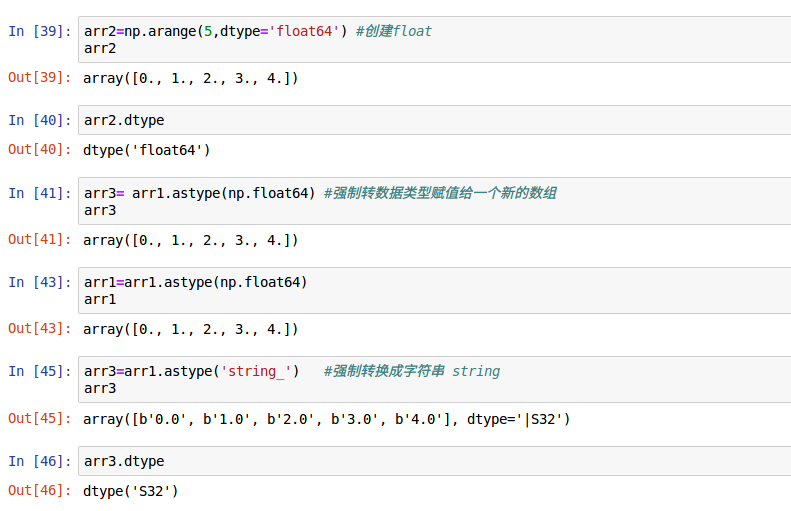
3.1.2 数据类型转换
数据类型可以在数组创建时通过给属性dtype赋值指定,也可以调用BIF astype(np.float64),astype(np.int32)或者astype('string_')强制转换。
3.1.3 数组形状的改变(重塑,合并,拼接,拆分,转置,随机函数)
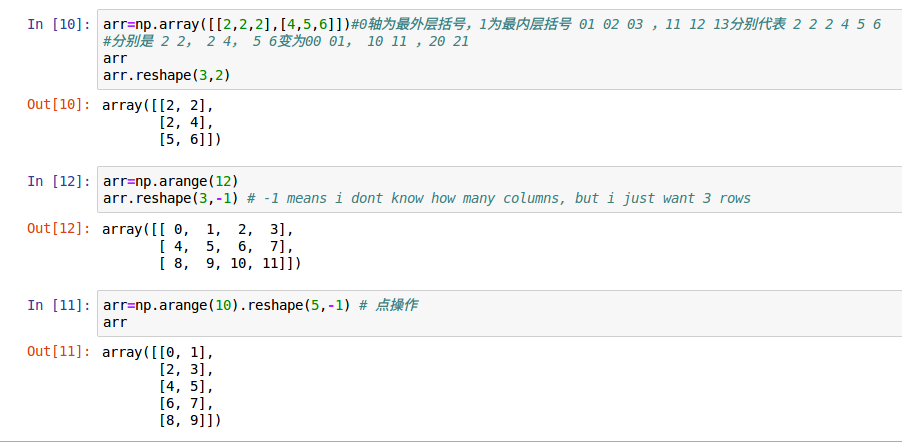
3.1.3.1 重塑
array_to_be_reshaped.reshape()。指定重塑的形状
3.1.3.2 合并
np.concatenate([arr1,arr2],axis)。指定被拼接的数组以及拼接方向,例子如下:
1: arr1 = np.arange(6).reshape(3,-1) 2: arr2=np.arange(6,12).reshape(3,-1) 3: arr3 = np.concatenate([arr1,arr2],axis=0) 4: arr4 = np.concatenate([arr1,arr2],axis=1) 5: arr3 6: arr4
输出arr3 arr4分别如下::
array([[ 0, 1],
[ 2, 3],
[ 4, 5],
[ 6, 7],
[ 8, 9],
[10, 11]])
array([[ 0, 1, 6, 7],
[ 2, 3, 8, 9],
[ 4, 5, 10, 11]])
得到arr3,arr4还有另一种方法,np.vstack((arr1,arr2))以及np.hstack((arr1,arr2))。
3.1.3.3 拆分
np.split(arr,[k,l]) #k,l为整数,代表将数组按照如下拆分 [0:k) [k:l) [l:end]
3.1.3.4 转置
transpose()指定一个新的数据轴,例如一个二维数组,默认的数据轴序列为(0,1)代表0轴1轴,转置变为(1,0)1轴变为原来的0轴。三位数值默认(0,1,2)转置后可变为(2,1,0),(2,0,1)等等。通过一个例子来说明:
假设有一个三位数组:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
0轴1轴2轴到底长什么样?如下图:
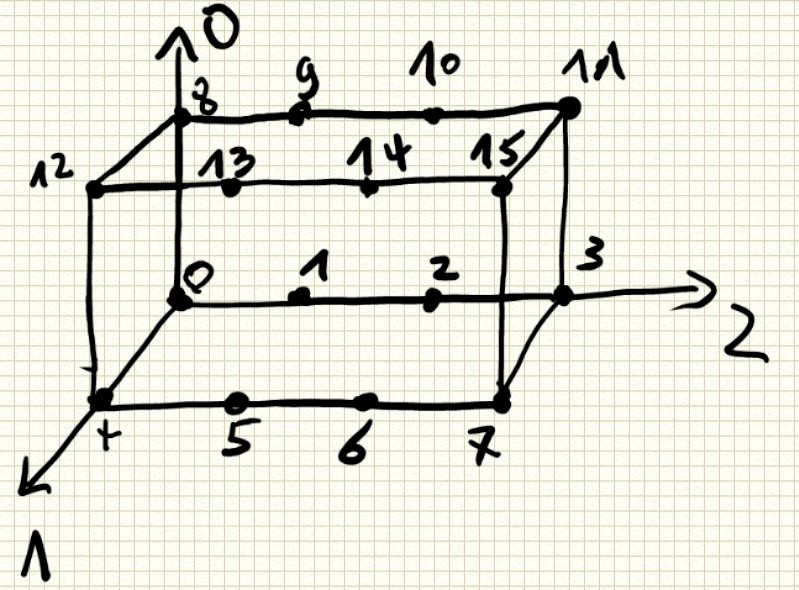
根据上面所说,最外层括号代表0轴,也就是说,从0轴看下去看到两个“面”,1轴看下去看到两根“线”,2轴看下去只看到4个点。 一个多维数组,最外层的square bracket代表0轴,依次往内推。当对arr.transpose((2,1,0))可知,看2轴的方式变为原来看零轴的方式,看0轴的方式变为原来看2轴的方式。
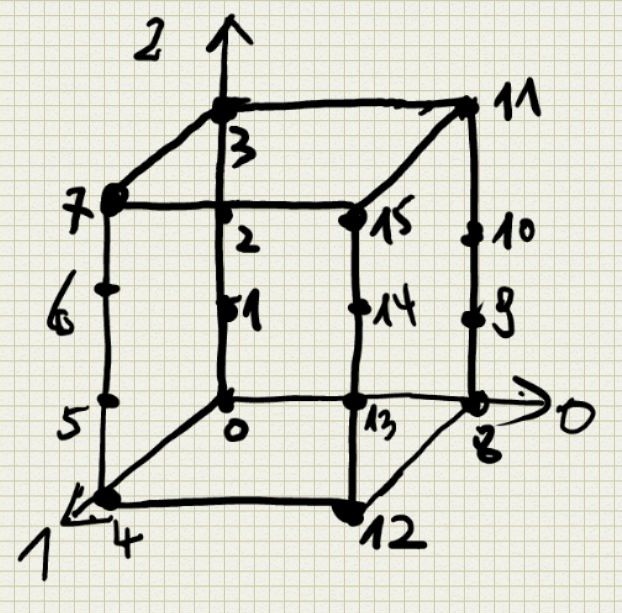
最终输出:
array([[[ 0, 8],
[ 4, 12]],
[[ 7, 9],
[ 5, 13]],
[[ 6, 14],
[ 2, 10]],
[[ 7, 15],
[ 3, 11]]])
3.1.3.5 随机函数
1: arr=np.random.randint(100,200,size=(5,4)) # generation of random numbers btw 100 and 200 size 5X4 array
3.2 数组的索引和切片
Numpy array的索引和切片使用方括号[]执行。
值得注意的是在切片时,即使把切片给一个新的变量,改变这个新的变量的值,原来的数组也会改变。切片为了批量处理数组的切片,可以理解为给这一片段一个新的“地址”而已。如果想要复制这一片段,以至于在操作时不改变原数组,要使用copy()函数。
此外,布尔索引可以使用真值表来进行索引。
3.2.1 索引与切片
- array的索引 index从0开始,-1索引代表倒数第一个,以此类推
- 切片array[m:n]表示取array[m]~array[n-1]
- 复制切片 new_array=array[m:n].copy()
- 多维数组的索引,可以使用连续的[m][n]或者[m,n],表示0-axis的m索引以及1-axis的n索引
1: arr=np.arange(10) 2: arr 3: 4: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) 5: 6: arr[3] 7: 3 8: 9: arr[-1] 10: 9 11: 12: arr1=arr[7:9].copy() #取第 7 8个切片 arr1改变 原数组无影响 13: arr1 14: 15: # 三维数组 16: arr1=np.arange(12).reshape(2,2,3) 17: 18: #切片 三位数组 无论在0axis 1axis上的哪里 只要是2axis的0,1 item 19: arr1[:,:,0:2] 20:
3.2.2 布尔索引
1: color =np.array(['red','blue','blue','green','red','green','red']) 2: datas=np.arange(21).reshape(7,3) 3: datas[color=='red']#取出datas的第0,4,6行
3.3 数组运算
3.3.1 基本运算,满足broadcasting 原则
1: arr*3 #乘法 2: 3: np.dot(arr1,arr2)#矩阵乘法, A*I=A 4: arr-3 #减法 5: np.abs(arr-3)#绝对值 6: np.square(arr)#平方 7: 8: arr1=[1,2,3] 9: arr2=[2,2,2] 10: np.add(arr1,arr2) #求和 11: 12: np.minimum(arr1,arr2) #最小值 1 2 3 分别与2 2 2比 13: 14: arr=np.random.normal(2,4,size=(6)) 15: 16: #modf将arr变为两个array,小数点之后的数组成的array和整数的array 17: np.modf(arr) 18:
3.3.2 判断运算
3.3.2.1 (x if condition else y) for x,y,c in zip(arr1,arr2,cond)
1: #如果c为真 那么x 否则y result为[1,6,7,4] 2: arr1=np.array([1,2,3,4]) 3: arr2=np.array([5,6,7,8]) 4: cond=([True, False, False, True]) 5: result=[(x if c else y) for x,y,c in zip(arr1,arr2,cond)] 6:
3.3.2.2 .where(condition, x,y)
1: #同样输出[1,6,7,4] 2: result=np.where(cond,arr1,arr2) 3: 4: 5: #判断condition 6: arr1=np.random.normal(-1,1,size=(4,3)) 7: new_arr=np.where(arr1>0,1,0) #输出arr1为正数的地方输出1负数为0
3.3.3 统计运算
For random samples from N(μ, σ^2), use: σ * np.random.randn(…) + μ
1: #N(3,6.25)的随机数放在2X4 array 2: arr=2.5 * np.random.randn(2, 4) + 3 3: 4: arr.mean()#算数平均值 5: #standard deviation 6: 7: #求某一轴的mean 8: #沿着axis1 最终结果得到两行的 mean 9: arr.mean(axis=1) 10: 沿着axis0 最终结果得到四列的 mean 11: arr.mean(axis=0) 12: 13: #求某一轴的和sum 14: arr.sum(0) #arr.sum(axis=0) 15: arr.sum(1)
3.3.4 排序
1: #生成1到4的随机整数,排序按照从小到大的顺序,数组变为被排序之后的数组 2: arr=np.random.randint(1,4,size=(4)) 3: arr 4: # array([2, 1, 3, 3]) 5: 6: arr.sort() 7: arr 8: # array([1, 2, 3, 3]) 9: 10: #看arr中的不重复的元素有哪些 并按顺序给出 11: np.unique(arr) 12: #array([1,2,3])
[[https://docs.scipy.org/doc/numpy-1.14.0/reference/generated/numpy.unique.html][unique函数]
Find the unique elements of an array.
Returns the sorted unique elements of an array. There are three optional outputs in addition to the unique elements:
- the indices of the input array that give the unique values,
- the indices of the unique array that reconstruct the input array,
- and the number of times each unique value comes up in the input array.
1: #生成1到4的随机整数,排序按照从小到大的顺序,数组变为被排序之后的数组 2: arr=np.random.randint(1,4,size=(4)) 3: arr 4: # array([1, 3, 2, 2]) 5: 6: #返回unique的value(返回的是已经排序的),以及每一个unique首次出现的索引值 7: u,indices=np.unique(arr,return_index=True) 8: u 9: # array([1,2,3]) 10: indices 11: # array([0,2,1]) 12: arr[indices] 13: #array([1,2,3]) 14: 15: #返回unique的value(返回的是已经排序的),以及原数组的数值在返回的unique value中的index,以方便重建 16: u1,indices1=np.unique(arr,return_inverse=True) 17: u1 18: # array([1,2,3]) 19: indices1 20: # array([0,2,1,1]) 21: u1[indices] 22: #array([1,3,2,2]) 23: 24:
3.3.5 线性代数运算包
1: from numpy.linalg import det 2: arr =np.array([[1,2],[3,4]]) 3: #行列式 4: det(arr) 5: #-2.0000000000000004
3.4 案例– 灰度变化
1: from PIL import Image 2: import numpy as np 3: im=np.array(Image.open('/path/of/image')) 4: print(im.shape,im.dtype) 5: 6: b=[255,255,255]-im #灰度变化 7: new_im=Image.fromarray(b.astype('uint8')) 8: new_im.save('/path/of/changed/image')